- Generative models for audio are really catching up and some tools, such as WaveNet and Juxebox, are definitely worth trying
- Google’s Magenta is putting out a lot of cool tools, especially Magenta Studio
- There are some commercial tools out there that explore related ideas: Algonaut, Regroover, and Factorsynth
- There are also some promising research projects, such as Flucoma
How I Made an Album Without Knowing Anything About Music
Could a software engineer with a background in artificial intelligence and no theoretical or practical knowledge about music make an album?
This was the challenge that led me into a two-year exploration and state-of-the-art project in computational creativity.
During this time, I created a set of tools that allowed a music illiterate like myself to create electronic music tracks in a fast and efficient way by automating some of the most crucial elements of the music production process, while retaining a high level of creative control.
On this page, I will be explaining in detail which set of techniques and ideas are powering these tools, as well as provide a broad idea on how they fit into the creative process that led up to the release of my first album: Residuals.
Concatenative Sound Synthesis
One of the most interesting concepts I discovered during my initial research was concatenative sound synthesis. The main idea is simple: given a database of sound snippets, concatenate or mix these sounds in order to create new and original ones. The concept is vague enough to guarantee rich literature in solutions and ideas with plenty of interesting research projects, such as CataRT and earGram.
My previous experience with dimensionality-reduction techniques on different domains led me to believe that matrix factorization of spectrograms would be an interesting way to perform concatenative synthesis. Allow me to explain.
A spectrogram is a 3D representation of audio that displays which frequencies of a signal are active over time. Non-negative matrix factorization (NMF) can be applied to the spectrogram in order to decompose it into a set of units, each composed of a component and an activation.
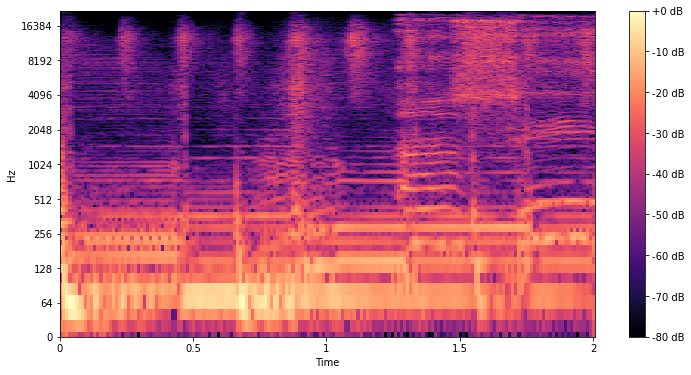
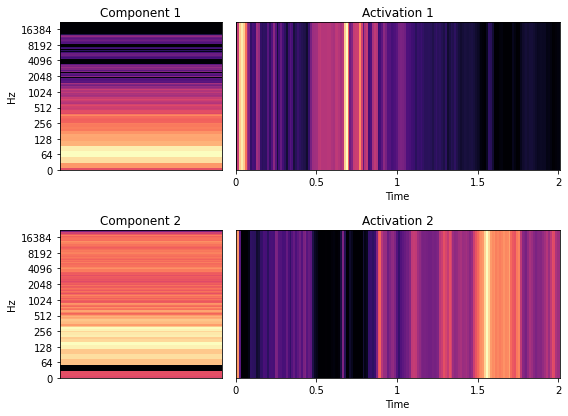
Components and activations can be seen as fine-grained representations of the original spectrogram. These elements decompose the original signal into separate units that, when joined together, are able to (approximately) reconstruct the original spectrogram. They also possess mathematical properties that allow us to perform some very interesting tasks.
First, each component and activation combination can be independently reconstructed. This means that NMF can be used as a non-supervised sound source separation technique, grouping related frequencies into units, in a lot of cases amounting to the instruments used in the original track.
| Original | Unit #1 | Unit #2 | Unit #3 | Unit #4 | |
|---|---|---|---|---|---|
|
Daniel Avery - Knowing We'll Be Here |
00:00 |
00:00 |
00:00 |
00:00 |
00:00 |
|
Holy Other - Yr Love |
00:00 |
00:00 |
00:00 |
00:00 |
00:00 |
|
DJ Python - Pq Cq |
00:00 |
00:00 |
00:00 |
00:00 |
00:00 |
swipe for more examples
Second, components and activations can be changed. For example, you can swap the components in a sound, effectively making one instrument sound like another.
| Source | Target | Result | |
|---|---|---|---|
|
Daniel Avery - Unit #2 vs Unit #3 |
00:00 |
00:00 |
00:00 |
|
Holy Other - Unit #3 vs Unit #4 |
00:00 |
00:00 |
00:00 |
|
DJ Python - Unit #2 vs Unit #1 |
00:00 |
00:00 |
00:00 |
swipe for more examples
This is not limited to the same source sound. We can swap components of different sounds, allowing us to make instruments sound like instruments from other tracks!
| Source | Target | Result | |
|---|---|---|---|
|
Daniel Avery - Unit #3 vs Holy Other - Unit #4 |
00:00 |
00:00 |
00:00 |
|
Daniel Avery - Unit #3 vs DJ Python - Unit #4 |
00:00 |
00:00 |
00:00 |
|
Holy Other - Unit #4 vs DJ Python - Unit #4 |
00:00 |
00:00 |
00:00 |
swipe for more examples
We can even replace all the components in a sound, while retaining the rhythmic structure but completely changing the way it sounds.
| Original | Remix | |
|---|---|---|
|
Daniel Avery - Remixed |
00:00 |
00:00 |
|
Holy Other - Remixed |
00:00 |
00:00 |
|
DJ Python - Remixed |
00:00 |
00:00 |
swipe for more examples
With these properties in mind, I created a tool that uses NMF to perform concatenative sound synthesis. This tool allows me to decompose an audio file into components and activations, then swap them with components from a database of good components, which I carefully built over time. This way, I can extract instruments from songs that I like and interactively find interesting variations for the way they sound.
Sound Source Separation
Another very interesting area of research in the audio domain these days is the identification and separation of specific sound sources. Given some audio, can we remove the vocals or extract the percussion?
With the advent of deep learning models, there was a substantial increase in the quality and availability of tools for this task.
| Original | Drums | Vocals | Bass | Other | |
|---|---|---|---|---|---|
|
00:00 |
00:00 |
00:00 |
00:00 |
00:00 |
|
|
00:00 |
00:00 |
00:00 |
00:00 |
00:00 |
|
|
00:00 |
00:00 |
00:00 |
00:00 |
00:00 |
swipe for more examples
After testing a few available open-source tools, I came to several conclusions. First, imperfect separations are sometimes the most interesting, especially the results from models trained to separate something that isn't in the source sound (e.g., extract vocals from an instrumental track).
| Original | Vocals | |
|---|---|---|
|
DrumTalk - Time |
00:00 |
00:00 |
|
Xonox - Transmission |
00:00 |
00:00 |
swipe for more examples
Second, it is hard to predict how good the separation on a sound source will be. Trial and error is your best friend here.
| Original | Bad Separation | |
|---|---|---|
|
Air - Lucky and Unhappy (Drums) |
00:00 |
00:00 |
|
BoC - Aquarius (Other) |
00:00 |
00:00 |
swipe for more examples
To help in the difficult task of finding good separations, I've developed a command-line tool that uses several models and parameter combinations to produce many different separations for a specific source of audio. This allows me to get a good overview of interesting separations that can be extracted. For example, if I like the percussion on a track, I let my tool produce dozens of different percussion separations, and then select which one sounds the best given the context I'm going to use it in.
Audio to Midi
Another extremely interesting and underrated task in the audio domain is translating audio into MIDI notes. Melodyne is state of the art in the area, but Ableton's Convert Audio to Midi works really well too.
| Original | Melodyne | Ableton | |
|---|---|---|---|
|
Aphex Twin - Avril 14th |
00:00 |
00:00 |
00:00 |
|
Air - J'ai Dormi Sous L'eau |
00:00 |
00:00 |
00:00 |
swipe for more examples
Both the concatenative synthesis and source separation tools allow us to extract fine-grained separations from an original sound source. I found that those tools create interesting, although imperfect, translations into MIDI. Resynthesizing this MIDI allows us to generate intriguing variations that "sound like" the original, although in unexpected ways.
| Separation | Resynth | |
|---|---|---|
|
Beck - Broken Drum (BoC Remix) |
00:00 |
00:00 |
|
BoC - Oirectine |
00:00 |
00:00 |
|
BoC - Oirectine |
00:00 |
00:00 |
|
BoC - Sixtyniner |
00:00 |
00:00 |
swipe for more examples
Putting Everything Together
All of these techniques became part of my music creation process.
I start by sampling loops from songs I like, and then use the concatenative synthesis and source separations tools to extract interesting musical ideas (e.g., melodies, percussion, ambiance). These results can be used directly, with a little FX (Replica XT, Serum FX), or translated into MIDI and resynthesized (Serum, VPS Avenger). This gives me the building blocks of the song (the tracks), each a few bars long, which I carefully combine using Ableton Live's session view into something that sounds "good".
Later, each track is expanded by sampling more loops from the original songs until I have plenty of content to create something with enough structure to be called a "song".
The biggest challenge in the whole process was dealing with imperfection. Concatenative synthesis commonly produces harsh-sounding results, sound source separations are rarely clean, and MIDI translations don't always make sense. Instead of obsessing over perfection and going down the path of carefully cleaning all the aggressive leftovers created by these tools, I decided to embrace imperfection and use it as the unifying theme of the album.
Melodies with unusual progressions, rough low-fi percussion, lush pads for masking undesired noises, and strange-sounding samples all give the album its distinctive character.
Future Work
During this project, I came across many references that I didn't have time to fully explore. Part of my future work will be investigating some of these ideas:
That's it! If you find any of this interesting, feel free to send me an email. Don't forget to listen to the album!